- 结果文件
- 使用指南
- 版本记录
- 联系客服
RGI main(Resistance Gene Identifier main)是CARD(Comprehensive Antibiotic Resistance Database)团队开发的核心工具,用于识别微生物基因组或宏基因组数据中的抗生素抗性基因(ARGs)。它通过比对输入序列与CARD数据库中的抗性基因模型,预测耐药性机制并注释相关基因。
本工具可用于对多个样本批量进行耐药基因注释。
输入文件:
包含待分析序列(FASTA格式)的文件夹或 *.zip 压缩包,要求每个分离株基因组序列文件后缀为 fasta/fna/fa/faa,文件名中避免出现空格或中文字符,若需分隔符,建议使用下划线 '_'

小工具结果:
rgi_*/protein.txt
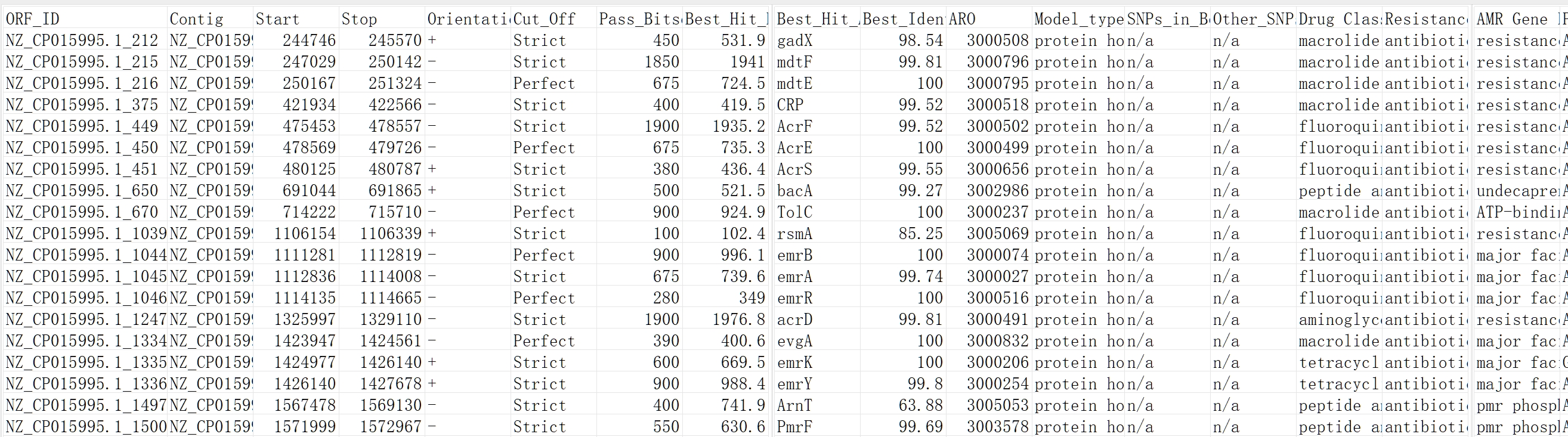
ORF_ID:检测到的 ORF(开放阅读框)编号;Start 和 Stop:起始和终止位置(若有);Orientation:ORF 链方向:+(正链) / -(负链);Cut_Off:筛选阈值策略:Strict(严格) / Perfect(完全匹配);Pass_Bitscore:ORF 通过预测模型的 bitscore 值(衡量匹配质量);Best_Hit_Bitscore:最佳匹配的参考序列 bitscore 值;Best_Hit_ARO:最佳匹配的 CARD 参考基因名称(ARO 标识;Best_Identities:与最佳参考序列的氨基酸相似度(%);ARO:匹配的 ARO 编号(CARD 唯一标识);Model_type:预测模型类型(如:蛋白同源模型);SNPs_in_Best_Hit_ARO:相对于最佳参考序列的 SNP 数量(n/a表示无数据);Other_SNPs:其他 SNP 信息(n/a表示无数据);Drug Class:耐药药物类别(多个以 ;分隔);Resistance Mechanism:耐药机制;AMR Gene Family:耐药基因家族;Predicted_DNA:ORF 的预测 DNA 序列;Predicted_Protein:ORF 的预测蛋白质序列;CARD_Protein_Sequence:CARD 参考数据库中匹配的蛋白质序列;Percentage Length of Reference Sequence:预测蛋白与参考蛋白的长度百分比(覆盖度);ID:唯一标识符;Model_ID:预测模型 ID;Nudged:未修正为完整 ORF 的标记(默认为空或 0);Note:备息;Hit_Start/ Hit_End:匹配在参考序列上的起止位置;Antibiotic:抵抗的具体抗生素(多个以 ;分隔)
软件版本:Resistance Gene Identifier - 6.0.4
参考文献:
Alcock et al. 2023. CARD 2023: expanded curation, support for machine learning, and resistome prediction at the Comprehensive Antibiotic Resistance Database. Nucleic Acids Research, 51, D690-D699 [PMID 36263822]
当前版本为1.0版本,上架时间为:2025-10-09